Операторы Яндекс.Вордстат

Краткое содержание статьи:
«Яндекс. Вордстат» — бесплатный онлайн-сервис, позволяющий отследить частоту поисковых запросов. Позволяет сформировать семантическое ядро при разработке нового сайта, проанализировать сезонность ключевика и его востребованность в отдельных регионах и населенных пунктах, а также определить наиболее популярные слова, которые чаще всего спрашивают пользователи.
Сервис не требует особых навыков использования — достаточно ввести слово либо словосочетание в поисковую строку, и система мгновенно выдаст результат. Однако он может оказаться не совсем релевантным, так как в него заложены все слова из этого выражения, а также сопутствующие с ней понятия.
В таком режиме Wordstat не учитывает отдельно падежи, единственное или множественное число, а местоимения, союзы и предлоги считает стоп-словами. Так, слово «тертый» демонстрируется в параметрах общей частотности при введении слова «три».
Важно! Подробная статистика запросов предоставляется только за последние 30 дней.
Операторы «Яндекс.Вордстат»
Получить более точную информацию, соответствующую конкретным потребностям пользователя сервиса и найти рабочие ключи, помогают специальные операторы сервиса Wordstat. Они позволяют задавать необходимые уточнения к интересующим поисковым выражениям и исключить рутинную ручную работу.
Основные операторы
Кавычки («») — позволяют зафиксировать количество слов в конкретном выражении. При введении словосочетания «купить стиральный порошок» мы увидим статистику исключительно по этим трем словам. Однако система суммирует разный порядок их расположения, поэтому в выдаче результата учтется, например, «купить порошок стиральный», «стиральный порошок купить» и «порошок стиральный купить». Также статистика отражает все возможные варианты окончания слов.
Важно! Символы кавычки можно использовать только для всего выражения, а не для отдельных слов.
Восклицательный знак («!») — указание этого оператора перед началом слова, например, !яблоко !зеленое !продам позволяет зафиксировать точное окончание. В результате Wordstat покажет только такие словоформы. При этом порядок расположения слов внутри словосочетания не учитывается.
Дополнительные операторы
Минус (-) — позволяет исключить из показов все ненужные термины. Если первоначальный вариант «купить металлический лом алюминиевый и медный» преобразовать в «купить металлический лом -алюминиевый и -медный», то последние два слова в статистике уже не отобразятся. Символ ставится перед понятием без пробела.
Плюс (+) — используется с целью принудительного учета в интересующих выражениях предлогов и союзов, которые система по умолчанию считает стоп-словами. Если проигнорировать этого оператора удаление из фразы «я хочу пойти в кино» предлога и союза никак не отразится на статистике. Однако при обозначении символа «плюс» «+я хочу пойти +в кино» стоп-слова войдут в статистический подсчет.
Квадратные скобки ([]) — помогает зафиксировать нужный порядок слов в интересующем ключевике. В случае введения в строку сервиса фразы «забронировать на сайте отели Хайфы и Тель-Авива» он выдаст статистику со всеми возможными сочетаниями этих словоформ. Однако после помещения словосочетания в скобки «[забронировать на сайте отели Хайфы и Тель-Авива]» учтется только такое написание.
ИЛИ «I» — позволяет учитывать в статистике ключевиков сразу несколько фраз. Это особенно актуально, если наименование может быть написано на разных языках, например, Toyota и «Тойота». Указание символа позволяет ввести в командную строку Wordstat следующую комбинацию: «автомобили (ToyotaIТойота)». В результате в статистику обязательно попадет слово «автомобиль» с сочетанием любого из двух наименований японского бренда.
Круглые скобки () — группировка, позволяет применять сразу несколько операторов для введения сложных запросов. Эффективно используется совместно с символом или «I».
Как собрать запросы нужной длины
Ситуация №1
Иногда необходимо собрать большие выражения, включающие несколько слов. С этой целью следует использовать оператор «кавычки» и внутри прописать интересующее слово или цифру ровно столько раз, сколько слов в запросе требуется увидеть. Например, пользователь в результатах «Яндекс. Вордстат» хочет увидеть фразу из пяти слов, содержащую запрос «малина». Для этого вводится следующая комбинация «малина малина малина малина малина». Сервис идентифицирует это понятие в качестве любого слова в заданной длине. Это означает, что в ключевике один раз будет встречаться «малина» и четыре любых слова. Вот пример выдачи:
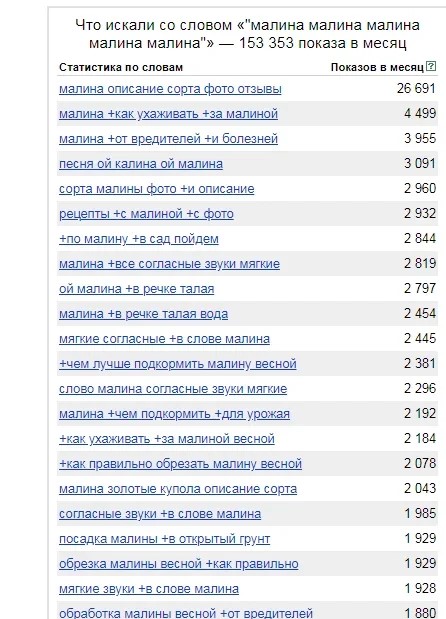
Подобная опция позволяет формировать длину желаемого запроса и иметь представление о выражениях, содержащих много слов. Это часто бывает актуально, так как Worastat максмимум демонстрирует 41 страницу результатов, где могут отсутствовать пятисловные запросы.
Недостаток такого подхода заключается в следующем. Если необходимо получить все длинные запросы, например, по фразе «мусорные контейнеры» (металлические бункеры для сбора и транспортировки отходов) не обязательно, что результаты будут именно по таким емкостям. Вот подтверждение:
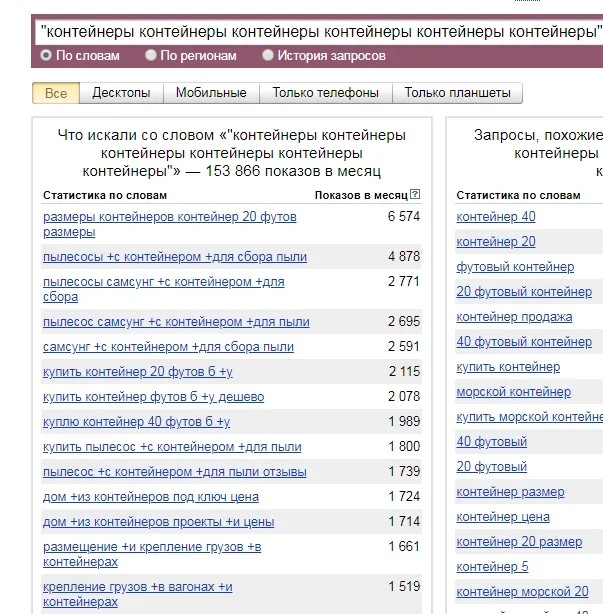
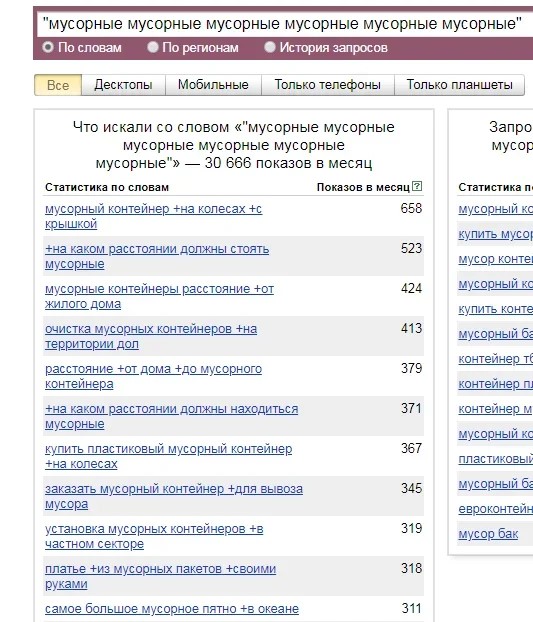
Аналогичная ситуация с шестикратным введением понятия «мусорный».
Чтобы сделать поиск релевантным в кавычках указываем обязательные слова и повторяем одно из них столько раз, сколько необходимо во ключевике. Получается «контейнер мусорный мусорный мусорный мусорный мусорный». В итоге сервис показывает следующий набор:
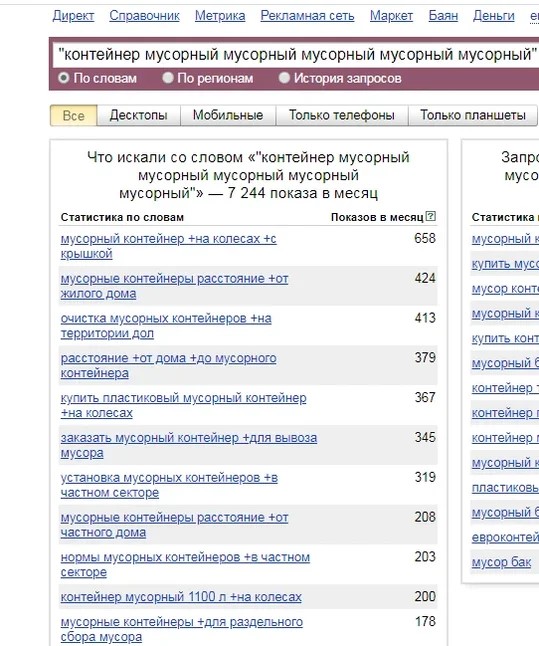
Можно видоизменить запрос и указать «контейнер контейнер контейнер купить мусорный контейнер». В этом случае система выдаст все шестисловные запросы, в которых обязательно будет присутствовать фраза «купить мусорный контейнер». Вот пример результатов такого поиска:
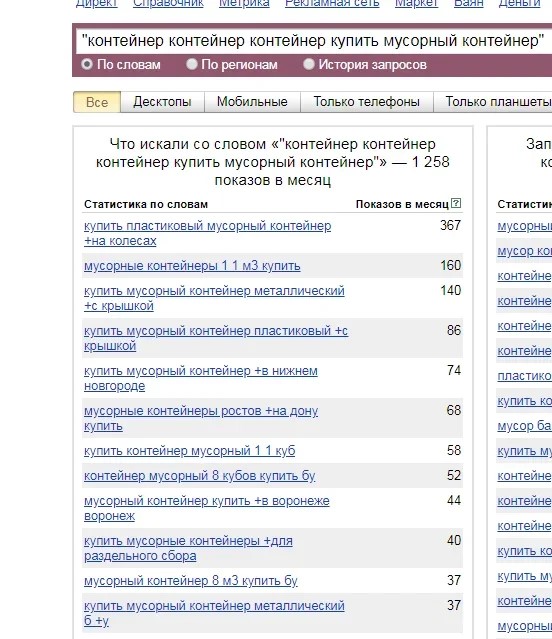
Ситуация №2
Существует множество рыночных сегментов, где часто встречаются запросы, не соответствующие направлению бизнеса. Их присутствие в результатах выдачи сервиса будет способствовать некорректной оценке потребительского интереса. Чтобы подобного не происходило их необходимо исключить из показа. Пользователю нужно указывать «кавычки» вместе с символом «восклицательный знак» для фиксации желаемой словоформы.
Например, необходимо увидеть точное количество запросов по фразе «купить планшет». Для этого в командной строке сервиса вводим такую комбинацию: «купить !планшет» и получаем следующий результат:
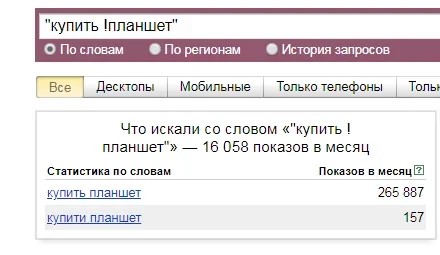
В выдаче перестанут показываться ключевики, где есть словосочетание «купить планшет», но которые нам не нужны для продвижения. Среди них «купить чехол на планшет», «купить зарядник для планшета», «купить батарею для планшета» и множество подобных.
Ситуация №3
Компании требуется отследить все возможные запросы по ключу или необходимо найти только коммерческие словосочетания для товаров, реализуемых под определенным брендом.
Для примера возьмем словосочетание «цифровой фотоаппарат Sony CyberShot. Потребители ищут такую фотокамеру, указывая десятки вариантов поискового запроса — «Sony CyberShot», «фотоаппарат «КиберШот», «фото CyberShot», «фотоаппарат Sony CyberShot» и другие. Чтобы не тратить много времени на сбор всех запросов сервис позволяет сформировать один регулярный код, включающий все поисковые фразы.
Применимо к указанному примеру он может выглядеть так: (цифровой фотоаппарат I фотоаппарат) (sony cyberShot I sony I cyberShot I сони I киберщот) -отзывы -ремонт -поломки -детали -запчасти -видео. Вместе с оператором «минус» использовались стоп-слова, появление которых в выдаче нежелательно. Их количество задается на усмотрение пользователя.
Особенности работы с отдельными операторами
Операторы Wordstat имеют определенные особенности и ограничения использования, которые необходимо учитывать при работе. Если ввести в командную строку кавычки либо квадратные скобки система станет автоматически учитывать все слова внутри фразы, включая союзы и предлоги. Это исключает необходимость ставить перед словами символ +.
Внутри символов «» и [] невозможно прописать минус, () и «I». В таком случае сервис укажет на некорректный запрос. При этом внутри круглых скобок квадратные употребляются. Кавычки не применимы к части фразы. Если ввести такой формат словосочетания «диван купить» в кредит система покажет:
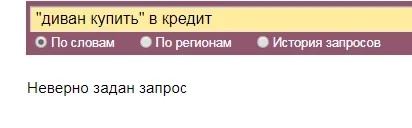
Какие обозначения Wordstat понимает в качестве словоформ?
Сервис считает за словоформы:
- глаголы и их спряжения, а также причастия/деепричастия (пройти, прошел, прошедший, пройденный);
- склонение имен существительных по числам и падежам (день, дни, днями, дней);
- замену суффиксов у глаголов (стоять, стоит);
- изменение «ё» на «е» и обратно (пчелка, пчёлка);
- падежное склонение числительных (пять, пяти, пятью);
- падежи, формы, числа, степени имен прилагательных (ниже, низший, нижайший).
Фразы не будут учитываться как словоформы в следующих случаях:
- различные ошибки и опечатки (молоко, малоко);
- сложные слова (водовоз, водо воз; пятиэтажный, пяти этажный);
- уменьшительно-ласкательные слова (ветка, веточка);
- сленговые слова (бабка, бабушка);
- транслитерация (гугл, google);
- глаголы, которые образованы с помощью приставок (принести, занести, унести);
- слова синонимы (емкость, бак, резервуар);
- существительные с различным родом (пес, собака);
- отдельные числительные с одинаковым значением, но неодинаковым написанием (8, восемь, восьмой).
Применение операторов «Яндекс.Вордстат» поможет быстрее и точнее искать ключевые запросы. Совместное использование нескольких специальных символов исключает монотонный процесс ручного подбора нужных поисковых фраз и отсеивания нерелевантных.