Чем опасны дубли страниц на сайте
Краткое содержание статьи:
Техническая оптимизация сайта включает в себя множество различных этапов. Особое место среди этих пунктов занимает отслеживание и устранение дублей страниц. Они могут быть полными и неполными. Например, в первом случае это зеркала главной страницы — site.ru и www.site.ru. Неполные дубли проявляются, как одинаковые участки текстов на разных URL-адресах. Такие копии важно найти и удалить.
Опасность дублей на сайте
Поисковые системы негативно реагируют на совпадающий материал в пределах одного ресурса. Из-за их появления могут понизиться позиции сайта или появиться фильтры. Вот основные опасные моменты, которые возникают на портале, если поисковый робот обнаружит дубль страницы:
- Определение неверных релевантных URL-адресов в поисковой выдаче. Робот не может точно определить, какая страница является реальной, а где дубль. Из-за этого начинают скакать позиции, сайт опускается всё ниже.
- Неправильное распределение ссылочного веса. Закупка внешних ссылок заканчивается тем, что происходит путаница с URL-адресами. Появляются рекомендации пользователей интернета на дубли, а не на основной ресурс. Робот такое поведение расценивает плохо, отправляет сайт под фильтр.
- Контент становится неуникальным. Копии текстов и картинок — это негативное влияние на ранжирование всего портала. Поэтому нельзя вставлять одинаковую информацию на разных URL-адресах. Продвигайте страницы сайта по разным ключевым запросам.
- Поисковики Google и Яндекс могут наложить санкции на портал. Манипуляции с дублями страниц воспринимаются роботами этих систем, как способ манипуляции для попадания в верхние строчки выдачи. Не хотите фильтров — боритесь с таким контентом!
К сожалению, многие владельцы сайтов не знают об опасности дублей страниц. В целях экономии они используют одинаковые тексты на страницах и потом удивляются, почему их ресурс занимает нижние строчки в поисковой выдаче.

Как появляются дубли страниц на сайте?
Перед тем, как заняться их поиском, нужно понять причину их появления. Дубли страниц на сайте чаще всего возникают по следующим причинам:
- Применение системы управления контентом. Сбой возникает, когда запись на портале может относиться к различным рубрикам или разделам. При этом их домены включены в адрес сайта самой записи. Часто такое встречается на информационных ресурсах или в блогах. Поэтому важно контролировать работу CMS.
- Ошибки в технических разделах. Часто такое можно встретить в системах управлениях Bitrix и Joomla. Происходит это при нелогичной генерации одной из функций сайта — регистрации, фильтра или внутреннего поиска. В этом случае появляются дубли, но URL страницы не учитывается.
- Человеческий фактор. С любым сайтом работают люди, которые пишут тексты и проводят оптимизацию каждой страницы. Но даже специалист может ошибиться или где-то полениться. Часто такое происходит с текстами, когда нет времени писать разный контент.
- Технические ошибки. Если к несовершенной работе системы управления контентом добавить человеческий фактор, то возникают странно прописанные адреса. Часто они являются дублями каких-то страниц.
Невозможно избавиться от дубликатов на сайте, если не уметь их находить. Поэтому каждый владелец ресурса должен понимать, как это делается.

Поиск дублей
Копии на портале можно искать несколькими проверенными способами:
- использование программы XENU (Xenu Link Sleuth). Она поможет отыскать не только дубли, но и битые ссылки. Программу используют для поиска полных копий. XENU требует скачивания на свой компьютер, разработана только для операционной системы Windows. С установкой программы не должно возникнуть сложностей. Во время ввода страницы для проверки, обращайте внимание на наличие символом слеш «/» в конце.
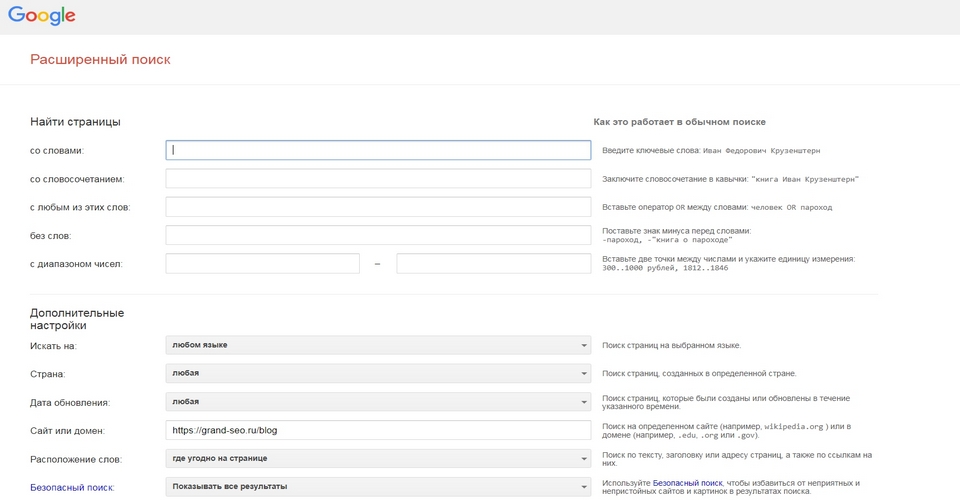
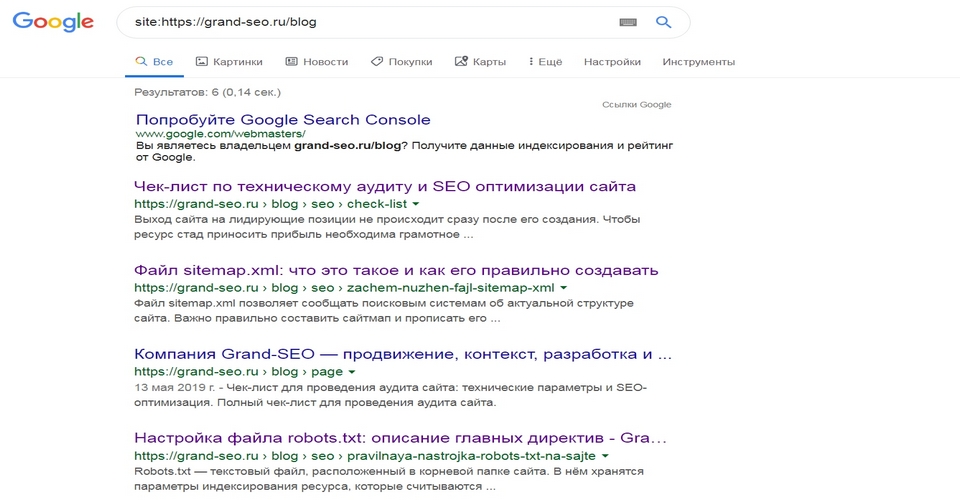
- с помощью расширенного поиска Google. В строку поиска нужно вставить адрес главной или интересующей страницы. После этого система предложит полный список страниц, которые проиндексированы. Проанализировав его, можно отыскать копии.
- с помощью web-мастерской Google. Владельцу сайта нужно будет пройти регистрацию. Увидеть копии страниц можно в разделе «Оптимизация Html». Ещё там будет представлен список одинаковых <Title>. Но неполные дубли этим методом не отыщешь.
- за счёт seo-платформа Serpstat. Для работы придётся пройти регистрацию.Выбираем раздел «Аудит сайта», потом «Суммарный отчёт». В течение определённого времени система покажет дублей Title, Description, H1. В бесплатной версии ресурса имеются ограничения, но информации достаточно для выявления копий.
Отыскав все дубли страницы, и проанализировав причины их появления, можно смело начать их удалять. Ни в коем случае не игнорируйте эти пункты, иначе копии снова начнут возникать на портале.
Простые способы удалить дубли страниц на сайте
Копии в Title, Description и H1 исправляются в ручном режиме. А дубли страниц устраняем этими способами:
- Через robots.txt — это самый лёгкий вариант. Необходимо только прописать нужные директивы.
- Воспользоваться 301 редиректом. С помощью этой директивы можно перенаправить роботов поисковых систем с дубля на оригинальную страницу. 301 редирект сообщает о том, что странички больше не существует.
- Link rel=»canonical» — вариант подходит для страниц с разными URL, но одинаковыми тестами. В код имеющегося дубля необходимо внедрить следующий тег — <link=»canonical» href=»http://site.ru/cat1/page.php»>. Он указывает на страницу, которая нуждается в индексации.
Попасть под фильтры Panda и АГС может любой сайт с дублями. Поэтому от копий нужно избавляться в первую очередь. В противном случае это отразиться на ранжировании. Вы потеряете позиции в поисковой выдаче, следовательно, и потенциальные клиенты или читатели не смогут находить ваш ресурс.

Если самостоятельно отыскать и удалить дубли страниц на сайте не получается, то обратитесь за помощью к специалистам компании Grand-SEO.